PART 1 Foundations of Hybrid Intelligent Systems
1 Knowledge graphs and LLMs: A killer combination
1.1 Knowledge graphs
- Not been widely accepted because of the cost, intricate access patterns, resultant scattered information.
1.2 Large language models
- Foundation of LLMs is transfer learning.
- LLM = pretrained language model (PLM) with significant scale
- LLM building blocks
- Tokenization
- High-dim embedding
- Transformations & attention
- Large dataset for pretraining
- Transfer learning
- Generation capacity
1.3 KGs and LLMs: stronger together
- Building KGs from unstructured data, Querying KGs, Summarizing
– LLMs have simplified this process - Hallucinations, Stale information, Explainability
– KGs can help overcome LLM limitations
1.4 The paradigm shift in data-driven applications
1.4.1 The four pillars of knowledge graphs
- Evolution
- Semantics
- Integration
- Learning
1.5 Building data-driven applications using KGs and LLMs
1.6 Knowledge graph technologies
- RDF and the SPARQL query language
- LPG and the openCypher, Gremlin query language
1.6.1 Taxonomies and ontologies
- Taxonomyies represent the hierarchical dimension of the data
- Ontologies support class definitions including union, complement, disjointness, and cardinality restrictions
- Rather than enforcing rigid, complete taxonomies, modern KGs integrate partial
- ontologies that can be extended organically.
1.7 How do we teach KGs and LLMs?
2 Intelligent systems: A hybrid approach
2.1 What is intelligence?
- 2 components: Knowledge representation & Reasoning
- There’s often a trade-off between how expressive a knowledge representation is and how efficiently it can be processed.
2.2 Designing an intelligent system
2.2.1 Definition of intelligent system
- Intelligent systems connect users to AI and ML to achieve meaningful objectives.
- An intelligent system is one in which intelligence evolves and improves over time, particularly when it improves by watching how users interact with the system.
2.2.2 Categories of intelligent system
- Intelligent autonomous systems: Full automation, real-time decision making, adaptability
- Intelligent advisor systems (IASs): Decision support, context awareness, user interaction
2.2.3 Characteristics of intelligent system
Essential 4 key characteristics:
- A meaningful objective
- The intelligent experience
- Knowledge creation and update
- Orchestration
Key aspects to consider:
- Focus on autonomous advisor systems
- Use an established knowledge base
- Learn from experience
2.3 Knowledge acquisition and representation
Knowledge acquisition
- KGs
- Transforming raw, structured or semistructured data into graph-based format.
- Directly convert to the KG or through inference engine (e.g., NLP, similarity comoputation)
- LLMs
- Ingesting vast amounts of unstructured text data.
- Training with neural network.
2.4 Reasoning
We have to consider how to deal with uncertainty, how to infer some of the knowledge we need, how to abstract to a broader understanding of the domain.
Deductive reasoning: general statement/hypothesis -> specific/logical conclusion
Inductive reasoning: samples of reality -> draws conclusion
LLMs & KGs – neither approach inherently possesses common-sense rea-
soning capabilities comparable to those of humans,
2.5 Reasoning engines
2.5.1 Limitations of pure deductive reasoning engine
- It requires a highly complete and accurate knowledge base, which is rarely available.
2.5.2 Using inductive reasoning and ML
- Converts unstructured text into structured data that can be incorporated into the knowledge base.
-> creation or extension of a KG - Make predictions or generate actions through inductive reasoning
2.5.3 The role of LLMs in the reasoning engine
- Probabilistic reasoning capability of LLMs : bridge knowledge gaps
2.6 A KG approach to IASs
- Bottom-up appraoch
- KG creation is driven by the available data rather than by the tasks we want to accomplish.
- Drawbacks: too may data sources, significant effort needed
- CRISP-DM
- Purpose-driven approach for KG construction
- More effective than bottom-up data integration strategies, which often lead to project failure
PART 2 Building Knowledge Graphs From Structured Data Sources
3 Create your first knowledge graph from ontologies
Data source’s local schema <-> Mapping <-> ontology’s reference schema
3.1 Knowledge graph building: Warmup
3.1.1 Business and domain understanding
Clinician diagnosing with Human Phenotype Ontology (HPO).
- A contextual description of the phenotype domain
- Data describing the relationship between phenotypic anomalies and diseases.
3.1.2 Data understanding
HPO repository
- RDF/XML file called hpo.owl
- serialized to Turtle (Terse RDF Triple Language)
- collection of triples: subject, predicate, object
- phenotype.hpoa
- phenotypic features associated with different diseases, including rare syndromes.
3.2 Understanding knowledge graph technologies
Two of the most popular approaches for creating KGs: RDF & LPG
Resource Description Framework (RDF)
- Defined and regulated by W3C.
- The file extension .owl stands for Web Ontology Language
- Each statement is composed of three elements (a triple)
- Subject – node (vertex) in the graph
- Predicate – relationship (edge) – defined globally
- Object – another node
- Particularly suitable for creating ontologies that describe a specific domain of knowledge.
(e.g., HPO ontology is serialized using RDF)
Labeled Property Graph (LPG)
- Provides a fast, query-based traversal of graph data and path analysis features.
- Support unique edges between nodes
- Can’t express the advanced semantics of RDF.
- Neo4j provide neo-semantic plugin to run basic inference -> can use RDF and it’s vocabs (OWL, RDFS, SKOS, etc.)
- Amazon Neptune provide the execution of Cypher queries on RDF data.
3.2.1 RDF or LPG? A goal-driven discussion
Table row to a KG edge
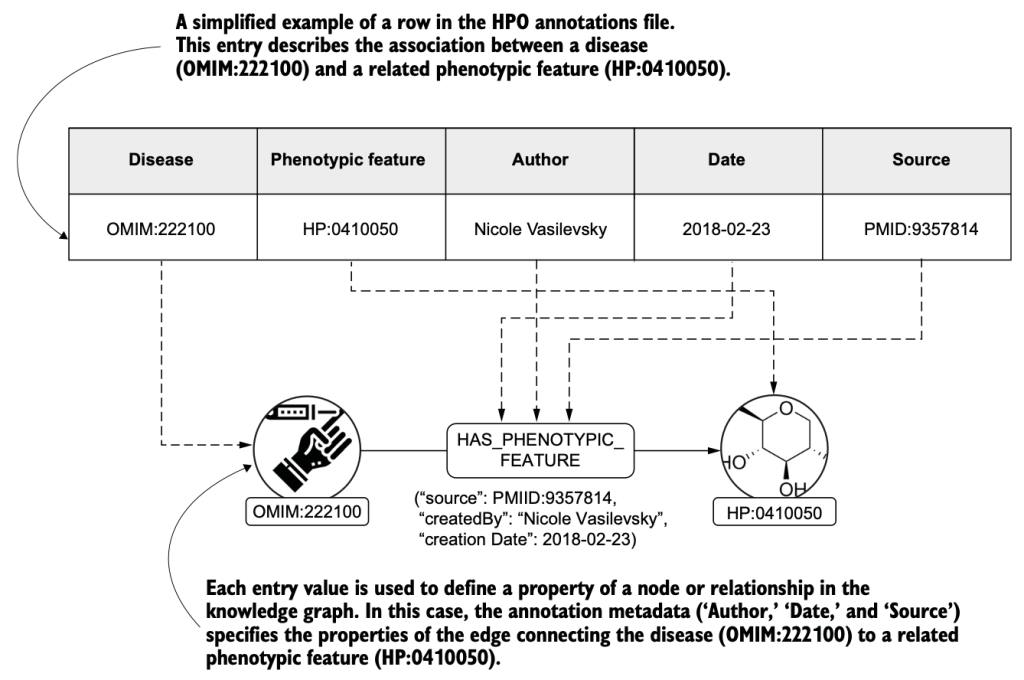
3.2.2 Representing edge properties with RDF and LPG
Three-part statements (triples) example: Alice → Bought → Car (Subject → Predicate → Object)
RDF: n-ary relations
- The blank node is typed as a :PhenotypicAnnotation and links a disease (identified by an OMIM ID) to a phenotypic feature (from the HPO). Additional metadata includes the data source (a PubMed ID), the author of the annotation, and the creation date.
- SPARQL query
- Retrieves metadata about a specific phenotypic annotation
- Data consumers can easily interpret and adapt to changes in the original schema
- Challenges related to backward compatibility and long-term maintenance
- Analogy: “The middle man”
- You create a node called “Purchase Event.” Then you connect everything to that event: Alice made the Purchase Event, the Purchase Event involved the Car, the Purchase Event cost $5,000, and the Purchase Event happened in 2024.
- It clutters up your database with a bunch of “event” nodes, making the graph harder to read and query.


RDF: named graphs
- Include a 4th element specifying that this statement is part of a named (sub)graph and can be considered a node of the RDF graph.
- The triple asserts that the disease OMIM:222100 has the phenotypic feature HP:0410050. Metadata about this assertion is attached to :Graph1
- Add complexity and inefficiency. Fine-grained updates can also be challenging.
- Analogy: “The file folder”
- You put the simple fact (Alice → Bought → Car) into a distinct “graph” or space, let’s call it Graph A. Then, you make statements about Graph A: Graph A happened in 2024, Graph A was verified by Bob.
- It can be clunky. If you just want to add a simple date to an edge, creating a whole new named graph (folder) for a single statement is overkill.


RDF: star (RDF*)
- An extension of RDF that narrows the gap between RDF and property graph models such as LPG.
- Analogy: “The quote”
- You put brackets around the main statement to treat it as one solid thing: <<Alice → Bought → Car>> → Cost → $5,000.
- It requires newer database software that specifically supports the RDF-star standard; older RDF tools won’t understand the brackets.


LPG
- LPG approach represents annotation details directly within the relationship, using key–value pairs.
- LPG model is well-suited for modeling metadata-rich relationships in a way that is expressive and accessible
- Analogy: “The Sticky Note on the Arrow”
- You draw a direct arrow from Alice to the Car. Right on that arrow, you fill out properties: [Price: $5,000, Date: 2024].
- Because it isn’t RDF, it doesn’t use standard web identifiers (URIs) or have the built-in logic/reasoning capabilities that make RDF great for linking global data across the internet.


3.3 Building a knowledge graph
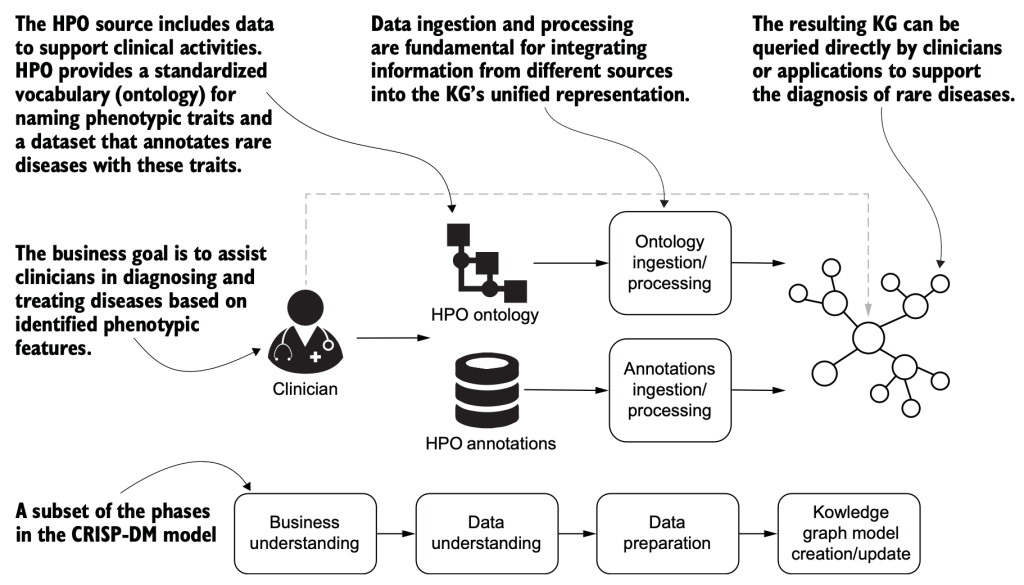
3.3.1 Ontology ingestion and processing with neosemantics
- Create and innitialize the database
- Establish constraints – to ensure uniqueness of the uri and id
Create indexes – to enhance access - Define initial configuration for the Neosemantics comoponent.
- 1st rule ignores the namespaces in the import phase
- 2nd rule encodes the relationship types in uppercase.
- Loading the vocabulary (numerous statements)
- Enriching nodes
3.3.2 Annotation ingestion and processing
- Load TSV files (HPOA file)
- Create nodes for A, then create relationships between A and B nodes.
- Add relationship properties in the for of key-value pairs.
- Enriching with more properties.
- Cleaning the KG by removing unnecessary nodes and relationships.
3.4 Querying the data
Clinicians can query the KG!
3.5 Reasoning over the KG
The use of the Neosemantics plugin highlights the power of semantic # in
enriching biomedical queries, enabling us to go beyond direct connections and tap
into the structure of domain knowledge.
4 From simple networks to multisource integration
4.1 Biomedical knowledge graphs and applications
Following case study will teach you how to select data sources to feed a KG and determine whether the information is sufficient to accomplish the required tasks.
4.2 Multi-omic applications of KGs
Let’s look at how to construct and analyze this simpler type of KG before moving to more complex scenarios that require merging multiple data sources.
4.2.1 Creating a KG from the PPI and protein-disease networks
4.2.2 High-level analysis of the resulting KGs
Louvain algorithm
4.2.3 Domain-specific analysis of the PPI and disease KG
3 Key measures
- Largest pathway component
- Density
- Conductance
4.3 Pharmaceutical applications of KGs
4.3.1 Deep analysis of the Hetionet knowledge graph
4.3.2 LLM-assisted interpretation of pathway analysis results
4.4 Clinical applications of KGs
4.4.1 LLM-guided clinical decision support analysis
Comprehensive KGs like Hetionet, the PPI network, and CKG serve as valuable testbeds for demonstrating integration techniques and analytical approaches.
This LLM-assisted analysis helps translate computational discoveries from KGs into
practical clinical decision-making, informing patient care and research protocols.